What's the value of a golden nugget?

Once upon a time I was a flashcard freak. I spent a decade hoarding facts and ideas into a collection of 30,000 cards that I reviewed obsessively with spaced repetition algorithms. Then I spent another three years recording podcasts about it.
We called the podcast “Golden Nuggets” because a recurring topic of conversation was the problem of knowledge valuation - how should you weigh the expected value of a flashcard you are considering adding to your collection?
I learned that people are as varied in their taste in flashcards as they are in their taste in music. Some like to extract insights from the biographies of great historical figures, others prefer the foundations of mathematics. Some are highly selective, even delicate connoisseurs of perfectly packaged factoids, while others prefer a more evolutionary approach, creating hundreds of flashcards in a sitting and letting future review sessions perform the Darwinian filter.
It’s difficult to know in advance how useful a particular flashcard will end up being. Scrolling back with the benefit of hindsight I can make rough judgements about which cards were worth creating: from the German vocabulary cards I never used and the extracts from random Wikipedia articles that ended up orphaned from the rest of my collection, to the programming cards that helped me find my first job.
What if I had been able to see every counterfactual world in which I added or removed a particular flashcard? What if I could have tried every possible combination and chosen between them based on how my life actually turned out? It would surely have told me something about what kind of knowledge I ought to value.
There’s a wonderful paper from 2021 called DreamCoder where the authors built a system that does something analogous to this, but with programs instead of flashcards. Rather than deciding in advance which concepts are worth knowing, the system discovers their value by testing them across thousands of problems and seeing which ones keep proving useful.

DreamCoder uses a so-called “wake-sleep” algorithm. During the waking phase, given a handful of input-output examples like [3,1,2] → [1,2,3], it searches over combinations of tokens in a simple functional programming language until it finds an executable program that can successfully transform all of the inputs to the outputs.
During the “sleep phase”, DreamCoder then refactors solutions to the problems it solved, abstracting out reusable functions into a shared library of concepts. The guiding principle for the refactoring is compression: a concept earns its place in the library if it makes solutions shorter across the entire corpus of tasks it was trained on.
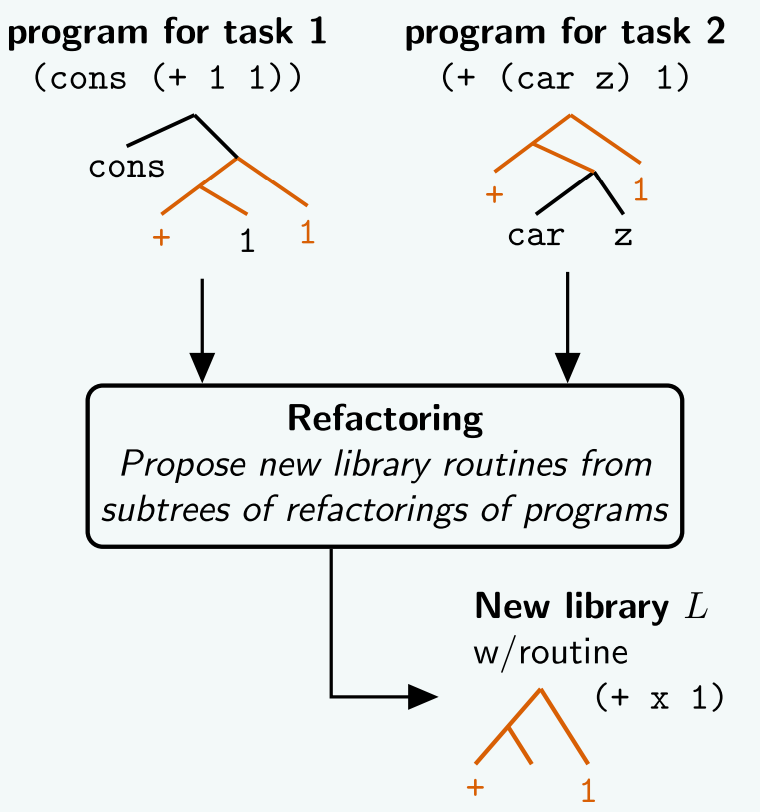
Once DreamCoder has built a library, it can search over combinations of library functions rather than raw primitives. Since library functions are higher-level, solutions expressed in them are much shorter, and shorter solutions are exponentially easier to find. A program to sort a list expressed in raw primitives requires 32 function calls and would take 10^73 years to find by brute force, but expressed using the learned library it requires only 5 function calls and is found in under 10 minutes.
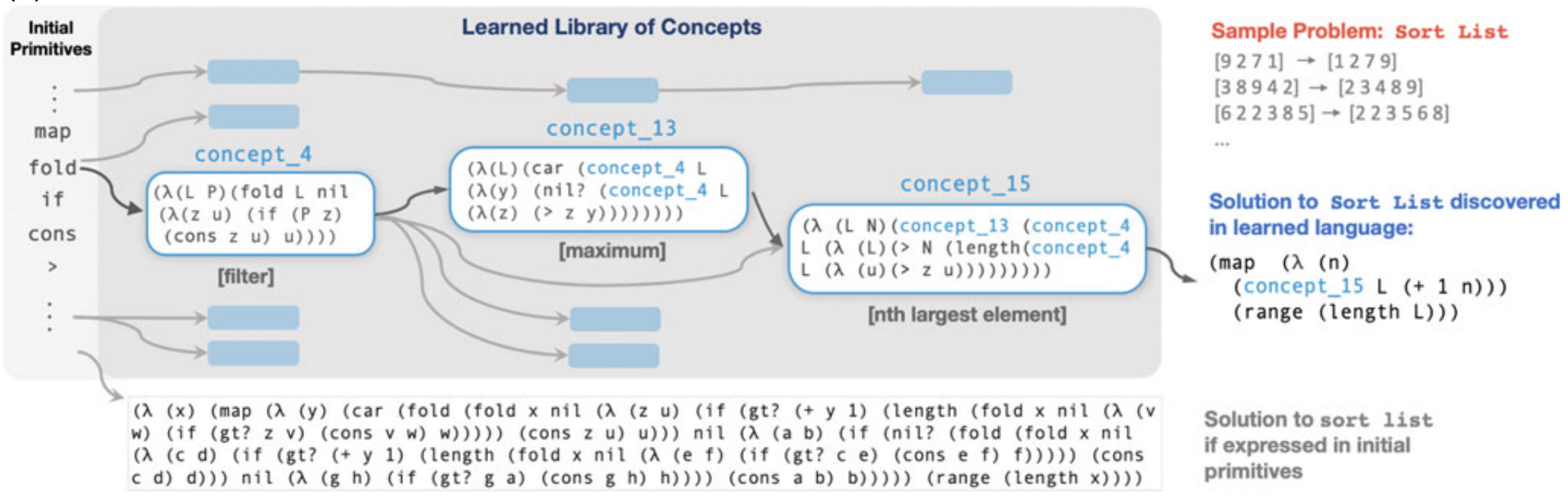
I realised when re-reading the paper recently it provides an interesting perspective on my question. It suggests that one of the ways you can value a golden nugget is in how well it reduces the search space for problems you haven't encountered yet. This would allow you to compare the value of pieces of knowledge - how much harder do remaining problems become when you remove it from your library?
What excites me is that LLMs allow us to run DreamCoder-style experiments over anything representable as text - not just programs, but theories, explanations, historical narratives, scientific concepts. We could investigate how individual ideas affect the search space for problems we haven’t yet encountered.
Take for instance DreamCoder’s “growing a language for vector calculus and physics” experiment:
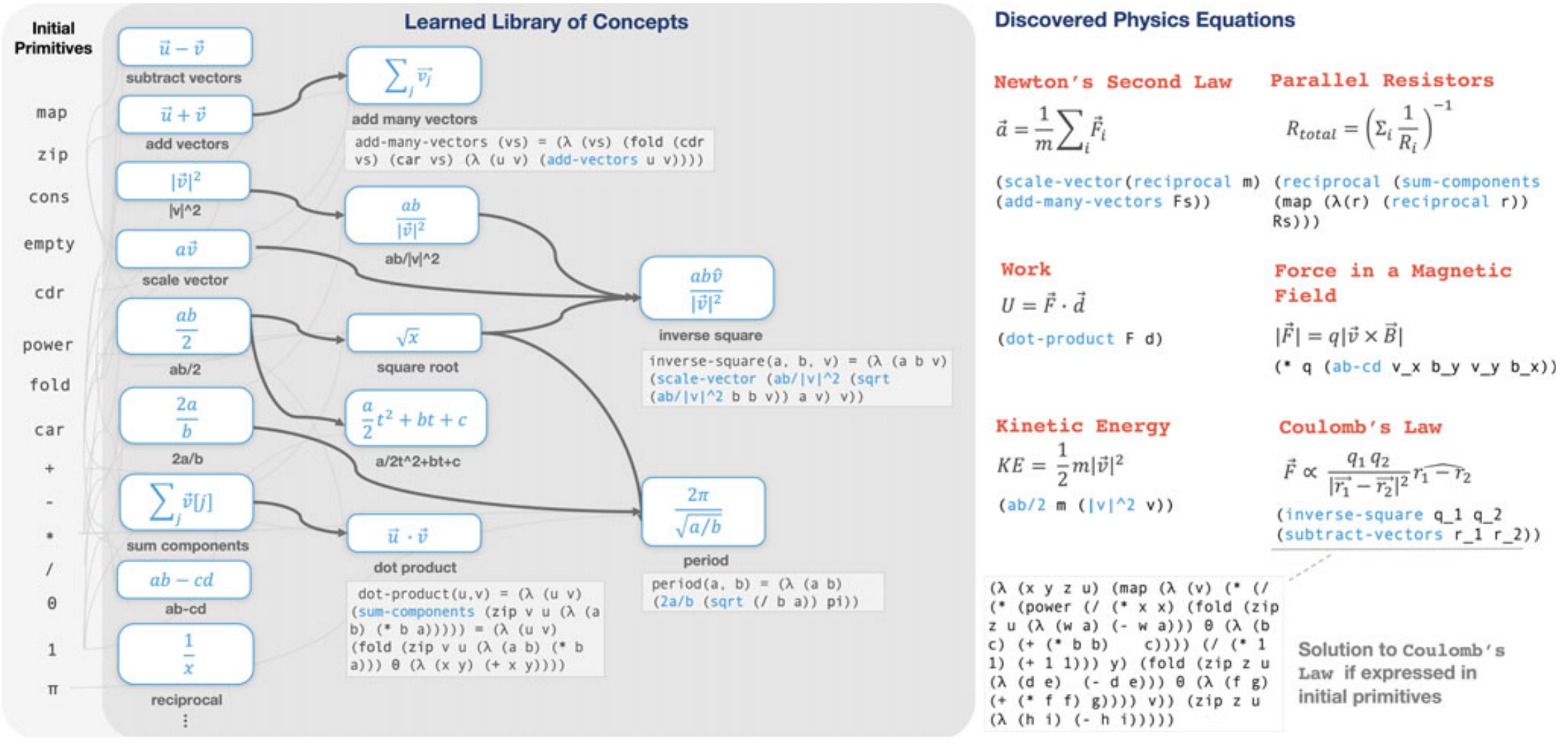
It reminds me of what Demis Hassabis has called the “Einstein test” for AGI - can an AI system trained only on data up to 1900s rediscover special relativity?
What if we inverted that experiment? Give the system all the conceptual ingredients Einstein needed and remove them one-by-one. Which are accidents of how Einstein happened to think about the problem? Could a system reconstruct the same physics from a different set of primitives entirely?
Beyond science, what if we could simulate the conditions of ancient Athens - a city of perhaps 100,000 people where the density of interesting minds per acre of the Agora may have been the highest in history - and test which ingredients were essential to that explosion of ideas?
Might it be possible to turn epistemology into a science?